Microsoft and MITRE release framework to protect Cyberattacks against AI

Microsoft also unveiled the Adversarial ML Threat Matrix, a tool to help cybersecurity experts plan attacks against artificial intelligence models, in partnership with the MITRE research association and a dozen other organizations, including IBM, Nvidia, Airbus, and Bosch.
There is an increase in critical online risks that jeopardize their protection and reputation with the implementation of AI models in many fields. The Adversarial Machine Learning (ML) Threat Matrix endeavors to collect different strategies utilized by malignant adversaries.
Several tasks are conducted by AI models, including the recognition of objects in photographs by evaluating the data they consume for unique typical patterns. To trick these models into making errors, the researchers created malicious patterns that hackers might inject into the AI programs. By subtly changing the objects’ location in each input image, an Auburn University team also managed to trick a Google LLC image recognition model into misclassifying objects in images.
The organizations have contributed with a series of adversarial AI framework weaknesses and hacking strategies to the Adversarial ML Threat Matrix that helps to investigate and resolve cyber-attacks. One example reveals a method of targeting malicious input data on AI models. Another package contains a situation in which attackers can duplicate an AI that helps the attacker to uncover neural network weak points.
Organizations can utilize this structure to test their AI models’ versatility by imitating realistic attack scenarios. The mechanism can also be used by cybersecurity researchers to familiarize themselves with the risks their associations’ frameworks will experience in the immediate future.
Microsoft says that the structure’s goal is to place attacks on ML frameworks in a system that security experts can arrange themselves in recent and upcoming challenges.
Machine learning (ML) is vulnerable to adversaries’ attacks. This can range from an attacker trying to make the ML system learn the wrong thing (data poisoning), doing the wrong thing (evasion attacks), or exposing the wrong thing (model inversion). While there are many attempts to include comprehensive taxonomies of the forms of attacks against a machine learning device that can be performed, none are structured around organizational issues. In any case, operational concerns are ATT&CK’s objective.
The Adversarial ML Threat Matrix means to close the difference between scholarly taxonomies and organizational issues.
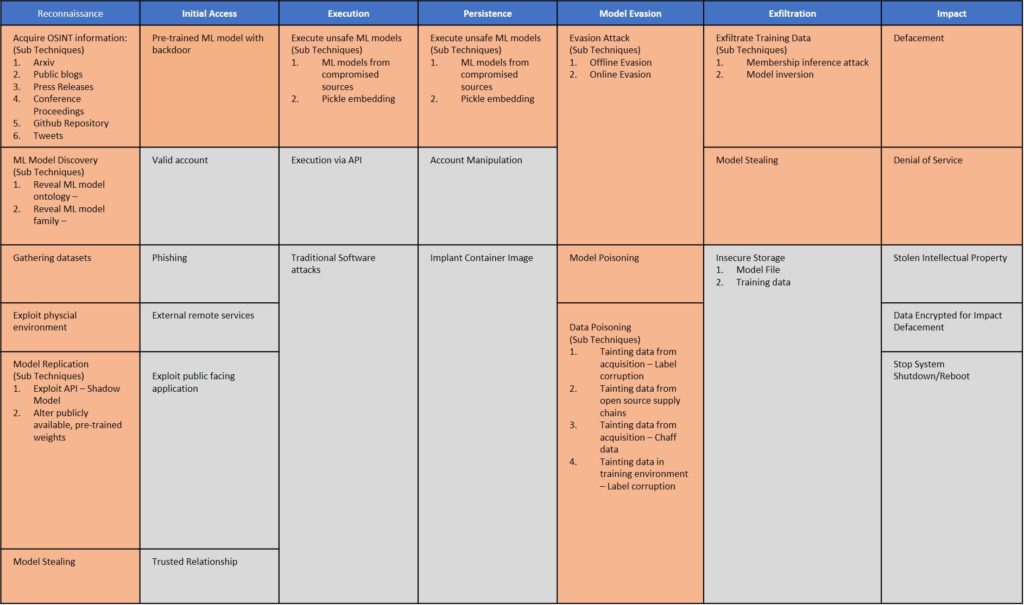
For instance, a Figure from Github indicates a subset of the Adversarial ML Threat matrix. At the top is the “Strategies,” which are designed according to ATT&CK and relate to the large categories of adversary behavior. Each cell is a “technique,” falling under a single strategy. Any of the approaches are special to Adversarial ML and are orange in color.
The remainder is shared with the original ATT&CK, although they may have a slightly different meaning in an ML context. Note that while the matrix is seen as a table, there is no prior association between cells in the same row. An attack would have a special pattern in which strategies are picked from tactics regardless of their order in the table.




