Experts Find A Way To Know Whatever Is Being Typed By A User During A Video Call

Another new assault method has been discovered by experts which can understand the keys pressed by the targeted user at the opposite end during the video conference call by utilizing only the video feed to connect displayed body movements to the content being typed/composed.
The examination was done by Mohd Sabra, and Murtuza Jadliwala from the University of Texas at San Antonio and Anindya Maiti from the University of Oklahoma, who said that the assault could be reached out past live video feeds to those that are streamed on YouTube and Twitch as long as the webcam’s field-of-view catches the targeted client’s noticeable movements of the upper body.
Researchers said that “With the recent ubiquity of video capturing hardware embedded in many consumer electronics, such as smartphones, tablets, and laptops, the threat of information leakage through visual channel[s] has amplified. The adversary’s goal is to utilize the observable upper body movements across all the recorded frames to infer the private text typed by the target.”
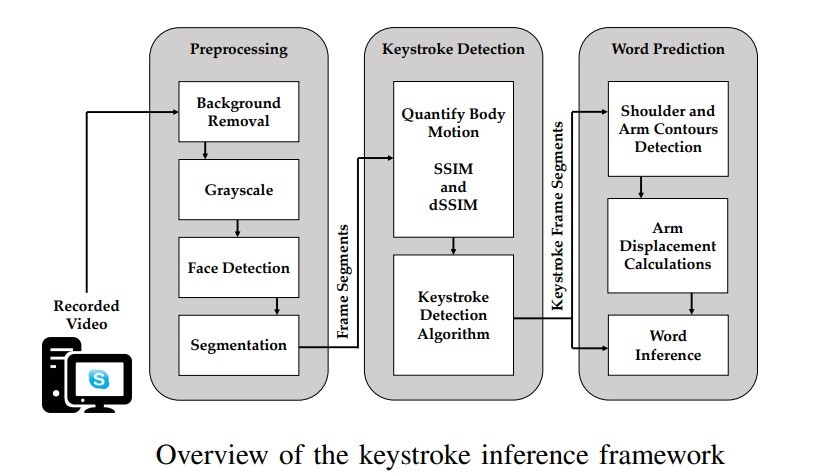
The video feed, recorded, is processed via a keystroke-based conclusion framework to accomplish this and it involves three different processes. First comes the pre-processing in which the background from the video is removed and is switched to grayscale, a model named FaceBoxes is then utilized to recognize face followed by segmentation of right and left arm areas.
Then comes the keystroke detection, where the frames of arms are extracted to process the Structural SIMilarity (SSIM) index measure with an aim to evaluate body movements that occurred among successive frames in every one of the left and right side of the video segments and detect frames where keystrokes actually occurred. Word prediction is the final step where the frames in which keystroke actually occurred are utilized to identify movements after and before every recognized keystroke which is then utilized to deduce explicit words by the use of a prediction algorithm based on a dictionary.
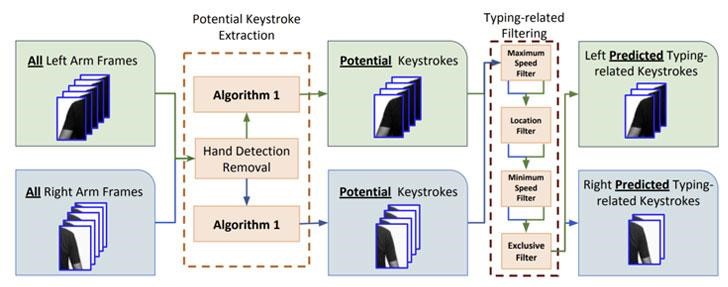
As such, from the vast number of recognized keystrokes, words are derived by utilizing the number of keystrokes distinguished for a word and also the direction and magnitude of arm relocation that happens between successive keystrokes of the word.
This relocation is estimated utilizing a PC vision method called Sparse optical flow which is utilized to follow shoulder and arm motions across frames of chronological keystrokes.
To identify the “ideal directions a typer’s hand should follow” by the use of both hands, a template built for “inter-keystroke directions on the standard QWERTY keyboard” is implemented.
The algorithm of word prediction, at that point, looks for the most accurate possible words that match the sequence and number of left and right-handed keystrokes and the direction of arm relocations with the inter-keystroke directions template.
Researchers claimed that they have tested this framework with 20 members, 11 being males and 9 being females, in a controlled situation, utilizing a blend of touch typing and hunt-and-peck typing techniques, besides testing the deduction algorithm against various backgrounds, webcam models, clothes, specifically the sleeve design, keyboards, and even different video-calling platforms like Zoom, Skype, and Hangouts.
The research explained that the hunt-and-peck typers and the ones who were wearing sleeveless garments were far more vulnerable to such types of assaults and so were clients that utilized Logitech webcams, bringing about improved word recuperation than the individuals who utilized other external webcams from Anivia.
The tests were rehashed with other 10 additional members, 3 being females and 7 being males, but this time it was done in a test home arrangement, effectively deducing 91.1% of the usernames, 95.6% email addresses, and 66.7% of the sites typed by members, however just 18.9% of the passwords and 21.1% of the English words composed by them.
Maiti, Sabra, and Jadliwala mention that “One of the reasons our accuracy is worse than the In-Lab setting is because the reference dictionary’s rank sorting is based on word-usage frequency in English language sentences, not based on random words produced by people.”
Research expressing that obscuring, pixelation, and skipping of frames could be a compelling alleviation ploy, said that the video feed could be joined with sound information from the call to additionally improve the identification of keystroke.
Researchers explained that “Due to recent world events, video calls have become the new norm for both personal and professional remote communication. However, if a participant in a video call is not careful, he/she can reveal his/her private information to others in the call. In this paper, we design and evaluate an attack framework to infer one type of such private information from the video stream of a call – keystrokes, i.e., text typed during the call. We evaluate our video-based keystroke inference framework using different experimental settings and parameters, including different webcams, video resolutions, keyboards, clothing, and backgrounds. Our relatively high keystroke inference accuracies under commonly occurring and realistic settings highlight the need for awareness and countermeasures against such attacks. Consequently, we also propose and evaluate effective mitigation techniques that can automatically protect users when they type during a video call.”
If you like this article, follow us on Twitter, Facebook, Instagram, and LinkedIn.




